Playwright進階篇(四):多語言與地區測試
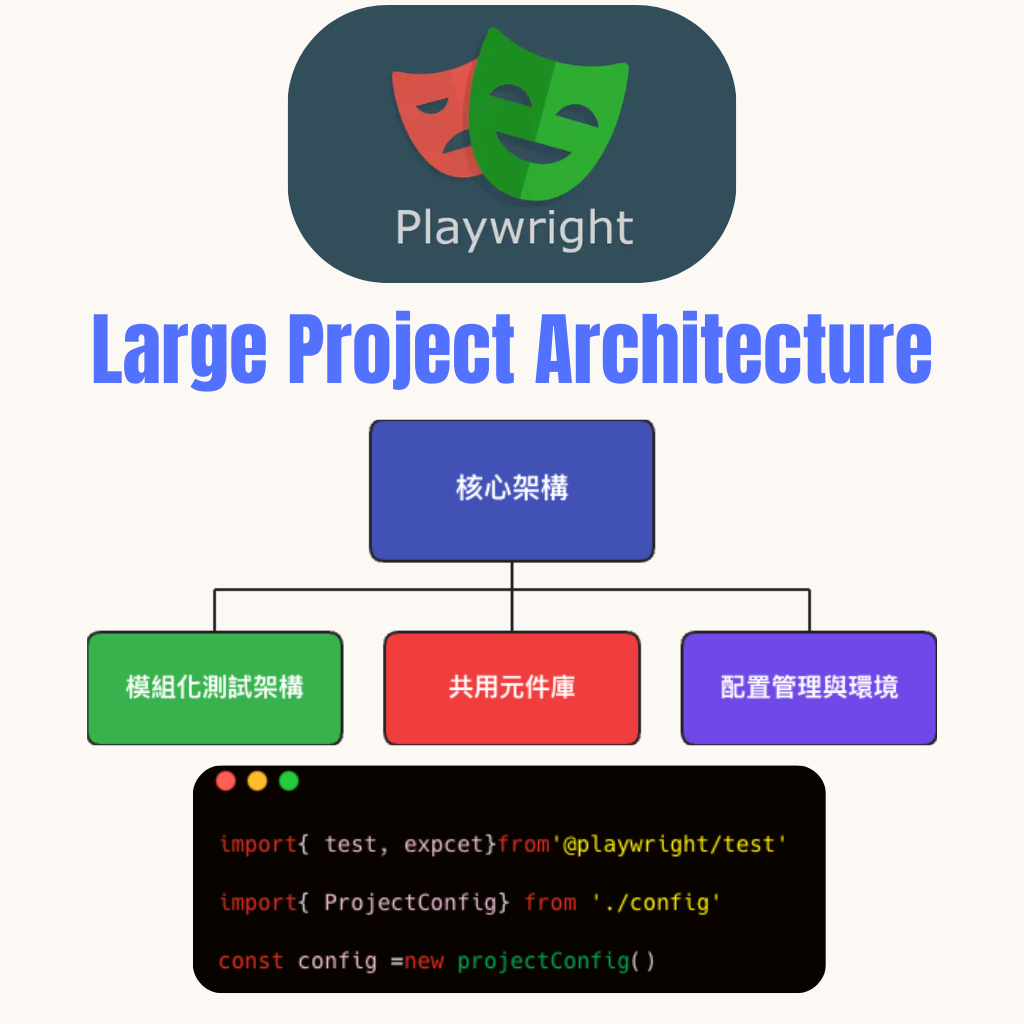
1.模組化測試架構
架構設計的重要性
在軟體開發的世界中,架構就像是一棟建築的藍圖。優秀的架構不僅僅是將代碼組織在一起,更是要創造一個靈活、可擴展且易於維護的系統。模組化是實現這一目標的關鍵策略。
模組化的核心理念
模組化架構的本質是將複雜的系統拆分成獨立且高內聚的模組。每個模組應該具備以下特徵:
- 單一職責:每個模組只專注於特定功能
- 低耦合:模組之間的依賴關係應該盡可能 minimal
- 高內聚:模組內部的代碼緊密相關
- 可測試性:便於編寫單元測試和集成測試
實踐意義
通過模組化,我們可以獲得諸多好處:
- 代碼重用:相似功能可以輕鬆在不同模組間共享
- 並行開發:不同的開發者可以同時在不同模組上工作
- 易於維護:問題定位和修復變得更加直接
- 擴展性:新功能可以很容易地添加到現有系統中
實作範例
# 定義用戶服務類,負責處理用戶相關的業務邏輯
class UserService:
# 構造函數,接收一個用戶驗證器作為依賴
def __init__(self, user_validator):
# 將驗證器保存為實例屬性,實現依賴注入
self.validator = user_validator
# 創建用戶的方法,接收用戶數據作為參數
def create_user(self, user_data):
# 首先使用驗證器檢查用戶數據是否有效
if self.validator.validate(user_data):
# 如果數據有效,執行創建用戶的邏輯
# 這裡可以添加數據庫操作、日誌記錄等具體實現
return True
# 如果數據無效,返回False表示創建失敗
return False
# 定義用戶數據驗證器類,負責驗證用戶輸入數據
class UserValidator:
# 驗證方法,檢查用戶數據是否符合基本要求
def validate(self, user_data):
# 檢查用戶數據是否包含必要的字段
return all([
# 檢查用戶名是否存在
user_data.get('username'),
# 檢查郵箱是否存在
user_data.get('email'),
# 檢查密碼長度是否符合最小要求(至少8個字符)
len(user_data.get('password', '')) >= 8
])2. 共用元件庫建立
為什麼需要共用元件庫
在軟體開發過程中,開發者經常會遇到重複編寫相似邏輯的情況。共用元件庫就是解決這一問題的有效方案。它就像是一個程式員的工具箱,存儲著可反覆使用的工具和方法。
共用元件庫的設計原則
設計一個優秀的共用元件庫需要遵循以下原則:
- 通用性:函數和工具要具有廣泛適用性
- 簡潔性:接口設計要直觀、易用
- 可擴展性:預留擴展和客製化的空間
- 文檔完備:清晰地說明每個元件的用途和使用方法
元件庫的實際價值
共用元件庫能帶來的顯著收益:
- 減少重複代碼
- 提高開發效率
- 統一代碼風格
- 降低維護成本
實作範例
# 導入必要的模組
import logging # 用於日誌記錄
from functools import wraps # 用於創建裝飾器
import time # 用於計算執行時間
# 日誌裝飾器:記錄函數的執行時間
def log_execution_time(func):
# 使用 wraps 保留原函數的元數據
@wraps(func)
def wrapper(*args, **kwargs):
# 記錄開始時間
start_time = time.time()
# 執行原函數
result = func(*args, **kwargs)
# 記錄結束時間
end_time = time.time()
# 使用日誌記錄函數執行時間
logging.info(f"{func.__name__} 執行時間: {end_time - start_time:.2f}秒")
# 返回原函數的結果
return result
return wrapper
# 輸入驗證裝飾器:檢查函數輸入的數據類型
def validate_input(input_type):
# 創建一個可以接收參數的裝飾器
def decorator(func):
@wraps(func)
def wrapper(value):
# 檢查輸入值的類型是否符合預期
if not isinstance(value, input_type):
# 如果類型不匹配,拋出類型錯誤
raise TypeError(f"預期輸入類型為 {input_type.__name__}")
# 如果類型匹配,執行原函數
return func(value)
return wrapper
return decorator
# 使用裝飾器的示例函數
@log_execution_time # 記錄執行時間的裝飾器
@validate_input(str) # 驗證輸入為字符串的裝飾器
def process_string(text):
# 將輸入的字符串轉換為大寫
return text.upper()
3. 配置管理與環境分離
為什麼需要環境分離
不同的運行環境(開發、測試、生產)往往有著截然不同的配置需求。環境分離確保了:
- 安全性:生產環境的敏感配置不會洩露
- 靈活性:可以快速切換和調整不同環境的參數
- 一致性:各環境配置可以通過標準化流程管理
配置管理的最佳實踐
優秀的配置管理應該做到:
- 配置與代碼分離
- 支持多環境配置
- 提供默認配置
- 支持動態配置更新
- 具備良好的安全性機制
環境分離的實際意義
通過科學的配置管理,我們可以:
- 簡化部署流程
- 降低環境切換的複雜度
- 提高系統的可移植性
- 更好地進行安全控制
實作範例
# 基礎配置類,定義所有環境的公共配置
class BaseConfig:
# 默認調試模式為關閉
DEBUG = False
# 默認測試模式為關閉
TESTING = False
# 默認數據庫連接字符串
DATABASE_URI = 'default_database_connection_string'
# 開發環境特定配置
class DevelopmentConfig(BaseConfig):
# 開發環境開啟調試模式
DEBUG = True
# 使用開發環境的數據庫連接
DATABASE_URI = 'development_database_connection_string'
# 生產環境特定配置
class ProductionConfig(BaseConfig):
# 使用生產環境的數據庫連接
DATABASE_URI = 'production_database_connection_string'
# 測試環境特定配置
class TestConfig(BaseConfig):
# 測試環境開啟測試模式
TESTING = True
# 使用測試環境的數據庫連接
DATABASE_URI = 'test_database_connection_string'
# 配置管理函數,根據環境名稱返回對應的配置類
def get_config(env):
# 配置映射字典,將環境名稱對應到配置類
config_map = {
'development': DevelopmentConfig,
'production': ProductionConfig,
'test': TestConfig
}
# 如果找不到對應環境,返回基礎配置
return config_map.get(env, BaseConfig)
# 使用示例:獲取開發環境配置
current_config = get_config('development')
總結與展望
大型專案架構設計是一門需要不斷學習和實踐的藝術。上述三個方面 - 模組化、共用元件庫和環境分離 - 構成了一個健壯且靈活的系統架構基礎。
補充說明:
- 在實際專案中,配置管理工具(如 Consul、etcd、Spring Cloud Config)可以幫助我們更好地實現環境分離和配置管理。
- 使用環境變數或配置文件來區分不同環境的配置,是常見且有效的做法。
- 在大型專案中配置管理是相當重要的一環,如果沒有做好萬一有重大的資安事件發生,損失會難以估計。
- 配置管理與環境分離能夠有效降低開發人員在不同的環境中部屬時,所產生的錯誤。
分享這篇文章:
相關文章

Playwright進階篇(五):自動化截圖與錄影
Playwright基礎篇(一):安裝環境與創建專案

Playwright進階篇(二):API 測試與攔截
Playwright基礎篇(二):基本執行選項
Playwright基礎篇(四):元素定位方法概述

Playwright進階篇(三):測試案例設計與管理指南
Playwright基礎篇(三):測試案例實作

Playwright進階篇(六):使用 Allure Report 整合測試報告

Playwright基礎篇(八):日誌與除錯

Playwright基礎篇(六):基本配置選項

Playwright基礎篇(五):基本操作方法

Playwright基礎篇(九):強化報告系統

Playwright基礎篇(十):進階功能CI/CD

Playwright基礎篇(七):斷言機制
